How to Turn Customer Support Into Data–Driven Product Improvements
Are your customer feature requests collecting dust? Here’s how to fix that.
Note from Len: This is a guest post from Sujan Patel.
If you’ve ever wondered how to build a system for improving your product through customer feedback—one that you’ll actually follow through on, rather than just collecting information—then you’re going to love this post. I found it tremendously useful, and we’ve already implemented some of these tips internally at Groove. Trust me: you’re going to want to do the same.
If you have a software product or web app, you’ve probably heard this one before from your customer service reps: “I always get X type of support request; you guys should work on improving that.”
Now, let’s walk through how this kind of scenario usually plays out…
You make a mental note to tell your developers – and maybe you actually remember to pass on the request. Even then, your message still has to overcome a number of hurdles – from being tracked, to prioritized, to acted upon – before anything will happen. When your team is already busy, it’s incredibly easy for these types of requests to fall through the cracks.
When feature requests aren’t consistently tracked and revisited, they can’t be managed or improved upon. This isn’t the kind of process you can cross your fingers and “hope” happens; instead, you need a data-driven solution for turning the product improvement requests your CSRs receive into real changes for your company.
How CSRs Can Support Product Improvements
To be clear, I’m talking about feature requests – not bug reports.
A bug report is a customer calling in and saying, “Hey, this feature I rely on (and pay for) isn’t working. I need help fixing it ASAP.”
A feature request, on the other hand, is a customer who reports, “Hey, you know what’d be cool? If you could make this feature that I use do this other thing that’d be helpful for me.”
Bug requests should be escalated first, as real revenue from existing customers is at stake. Feature requests must be managed more judiciously. You can’t spring into action and throw resources at every problem that’s raised. Some feature requests may be too cost-intensive to develop; others may apply to such a small group of customers that implementing them doesn’t make financial sense.
Of course, you won’t know that until you develop a product improvement tracking workflow – and that begins with your customer service reps.
Your CSRs are your front line. They’re often the people who have the most contact with your customers, and they may be the first people to hear about problems or missing features that are disappointing your customers. As such, it’s critical that you train them to approach customer calls with a data-driven, data-collection mindset.
There are tools, like Receptive.io, that can help you streamline this process. But If you don’t want to use one (or if you just want to understand how such a tool could help your development team), check out the manual approach below.
The Two-QuestionProduct Improvement Ask
The first thing you must do to implement a more data-oriented product improvement process is to train your CSRs to ask two questions when handling support tickets (or in any other customer interaction that results in a product improvement suggestion):
- What specific product improvement(s) would you like to see?
- On a scale of 1-10, how important is this feature to you?
Generally, the best times to ask these questions are after the support ticket issue is resolved, or when a live chat support conversation is wrapping up. Leave the specific timing to your reps’ discretion to find the appropriate opportunity.
For the first question, train your CSRs to ask customers to be as specific as possible. Getting vague feedback (for example, “Oh, it’d be nice if it could do this…”) won’t help your development team prioritize feature requests compared to something like, “I wish X feature behaved in Y way so that I could accomplish Z.”
For the second question, the subtext is, “How likely are you to discontinue use of the product if the product improvement isn’t introduced?” A customer might say a feature request is very important, but further inquiry by CSR might reveal they’re unlikely to cancel if it isn’t addressed (in which case, the request should be rated as no more than 5 of 10).
Finally, develop a tracking mechanism (for instance, an Excel spreadsheet, notepad or ticket system) to record responses gathered from customers for review by the dev team. As an example, GrooveHQ lists duplicate product requests in single Trello cards to measure the relative volume of individual suggestions.
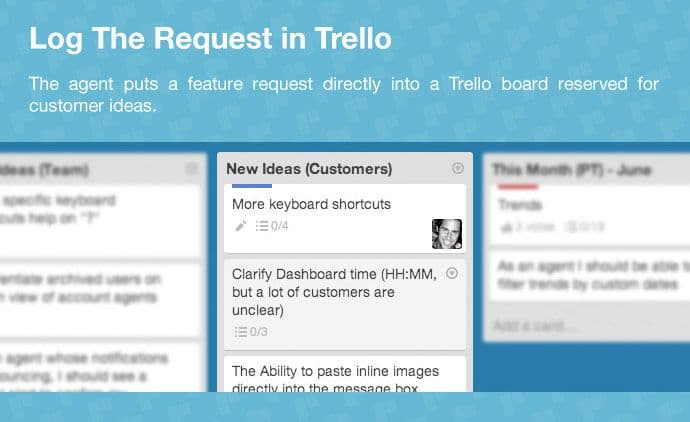
Converting Product Suggestions toProject Priorities
Once you’ve gathered feature request data from customers, along with their relative importance, you need to find a way to weight the suggestions and prioritize future dev projects.
Imagine the two scenarios below:
Scenario 1
A customer who has a lifetime value of $500 (compared to your average of $2,000) requests a feature that will be expensive for you to build, relative to other suggestions that you’ve tracked. When asked how important the feature would be to the customer, they indicate that it’d be nice, but that they wouldn’t cancel without it.
Scenario 2
Multiple customers with a lifetime value of $3,000+ mention wanting a feature that’d be quick and easy for you to implement, and that would make a major difference in their satisfaction with your program.
Kind of a no-brainer which of these you’d put into development first, right?
Of course, feature requests and their distribution relative to their importance are rarely this clean-cut. To develop your own prioritization system, you’ll need to establish your own set of internal priorities.
Potential factors that you may want to consider include:
- Client subscription rate (EX, $9/month basic plan vs. $49/month pro plan)
- Lifetime value of the customer
- The value of each customer’s referral network
- Any other metrics that help you define the value of a customer
- Relative difficulty of implementing the proposed improvement (scale of 1-10)
- The number of times each individual product improvement has been suggested
- Is the request building for your “ideal” customer, not your noisiest customer?
- Does the feature request support your vision?
- Will the feature help you expand your market?
Different factors will carry different weights for different companies. You may, for instance, place a heavier emphasis on difficulty of implementation than on the number of requests received (especially if you’re short on development resources). On the other hand, if your customer acquisition costs are high, you’ll want to focus more on the prioritization factors that will help you retain existing users.
In my case, one of my personal goals is to always be increasing the number of customers who “love our product,” as that’s a critical part of our growth (both Mailshake and LinkTexting bring in about 40% of new business through word-of-mouth). As a result, the factors I prioritize are the number of times a feature is requested and the impact that developing it will have on our market expansion (and turning customers into advocates).
Your selections will likely be different, depending on your company’s goals. Regardless, your goal – for now – should be to pick the 2-3 metrics that are most important to you so that you can develop an algorithm to score them using the process described below.
Prioritizing Your Feature Requests
We’re going to get a little technical here, so stick with me for a minute…
Above, I shared with you that I typically use two factors when prioritizing feature requests. Those of you who are thinking ahead have probably noticed one thing: these two factors could conflict with each other as my CSRs take comments from customers.
What if I get more feature requests for changes that won’t help me expand my market? What if the features I think will help us reach more customers aren’t the ones that current users are requesting?
If you’re measuring more than a single prioritization variable, you need a “tiebreaker,” if you will, that helps you make sense of which requests ultimately matter the most to your company.
To do that, you’re going to need an algorithm. If that sounds complicated, stick with me – I’m going to break the process down using an example so that you can apply this methodology to your own feature request lists.
Example: Product Improvement Priorities Spreadsheet
Imagine you have a SaaS product you sell to restaurants. As your customer service team takes requests from customers, they track them in a spreadsheet like the Product Improvement Priorities below:
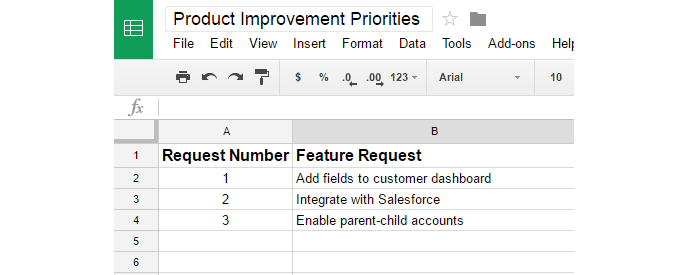
In this spreadsheet, you’ve assigned a new Request Number for individual feature request you’ve received. These can be as detailed or as broad as is helpful for your organization, but the goal is that, when a CSR takes a feature request, they can say either:
- “Yes, we’ve received this feature request before, and it’s been assigned number [x],” or
- “This is a new request we haven’t received before, so we’ll assign it a new Request Number.”
As you assign Request Numbers to different feature requests, you’ll create an individual page tab for each request number identified. These individual Request Number tabs are where you’ll create columns for each of the prioritization factors you assigned earlier.
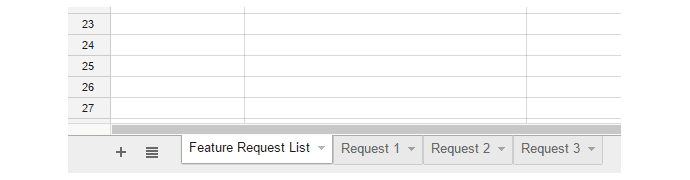
For the purposes of this example, let’s say you decide to prioritize the number of times a request is issued, the relative difficulty of implementation and the customer LTV with an equal weight. Therefore, whenever a new individual request comes in, you’ll create a new row detailing the date, customer and customer LTV (you or your CSRs may need other departments to help get this information).
You gather the following data for Request 1:
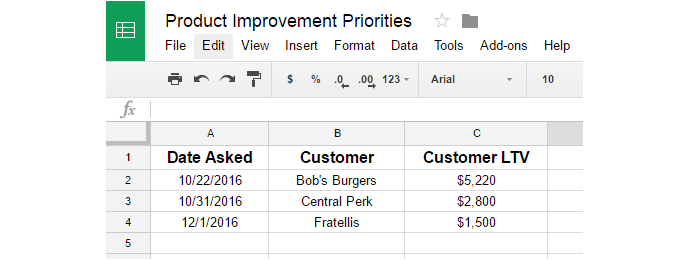
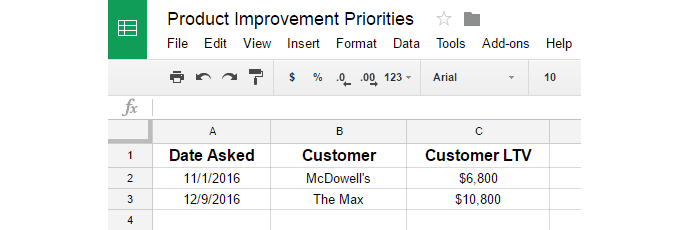
The following data for Request 2:
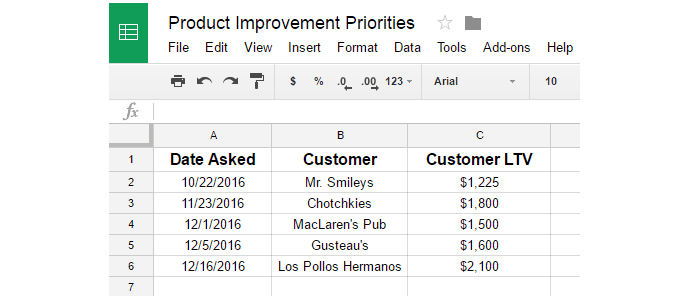
And the following for Request 3:
Now, because you’ve set each of these prioritization factors to receive equal weight, on the main tab, you’d add the following formulas to generate a monetary score for each request in Column D:
Request 1:
=(COUNT('Request 1'!A2:A4)*(AVERAGE('Request 1'!C2:C4)))
Request 2:
=(COUNT('Request 2'!A2:A6)*(AVERAGE('Request 2'!C2:C6)))
Request 3:
=(COUNT('Request 3'!A2:A4)*(AVERAGE('Request 3'!C2:C4)))
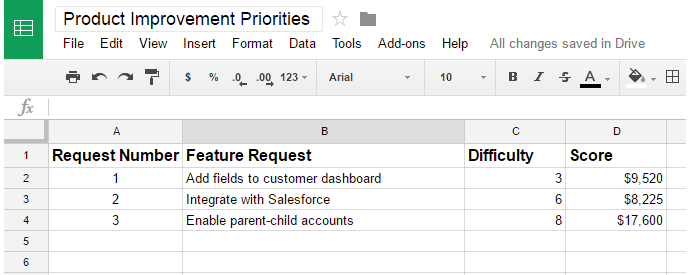
I’ve left the difficulty rating out of the equation for two reasons:
- Taking the average customer LTV times the number of times a given feature is requested gives me a rough idea of the monetary impact of the feature. The difficulty score affects my internal resource utilization – not the financial impact of the feature request (take a single score, say $17,600 from the spreadsheet above, and multiply it by 3, 6 and 8, and you’ll see what I mean).
- I find it helpful to be able to compare the monetary score and the difficulty score side-by-side, especially when values for different Request Numbers are similar.
But back to you. What can you conclude from this sample information?
Your analysis of the data may vary, but one read of these results would be that the monetary value of implementing Request 3 will be the most valuable – even though it’s the most difficult to implement and the fewest customers requested it.
You could also come to the conclusion that you should implement Request 1 before Request 2 – again, even though more customers requested Request 2 – both because it will be easier to implement and because it has a higher monetary score.
What If My Analysis is Wrong?
If you’re a skilled data analyst, this approach might look simplistic to you. And indeed, there’s a lot of wiggle room here. Maybe, you decide, your prioritization factors shouldn’t be weighted evenly. If, for example, you think your assigned difficulty scale should carry 2-3x the weight of the other variables, you’d want to adjust your calculations to reflect that.
You might also look at your results and decide to make a completely different call than what the numbers suggest. It could be that outliers are throwing off your averages, or that your final scores are all roughly equal, forcing you to make a judgement call.
My suggestion, for these reasons, is that you look at this as one decision-making tool in your arsenal – not the definitive word in your development priorities. Build your own algorithms based on your assumptions, but iterate them as you gather data on whether or not your estimated scores lined up with the real-world impact of the feature requests you’ve developed.
If you already have a more complex process for prioritizing feature requests, that’s great – stick with that. But if you don’t, the process above will give you tangible information to work off of as you begin to organize the number of feature requests being thrown your way.
Could you see something like this working for your company? Shoot me your thoughts by leaving a comment below.